Unraveling AI Jargon: What Exactly Are Large Language Models?
Everywhere we look, terms like "AI", "Machine Learning" and “NLP” are tossed around in headlines, but how many truly understand what Large Language Models are?
The field of Artificial Intelligence is not a bleeding edge topic in research and development. Believe or not, it was invented in the 1950s, and it is as old as color TVs, the microchip, and the first McDonald's franchise! It has been around since 1956 when the first algorithms laid the foundation for the mind blowing deep learning models we have today. If today we can have human-like conversations with ChatGPT or unlock our iPhones only using our faces, it is because of several increments done through the years in the Artificial Intelligence field. Artificial Intelligence, Machine Learning, Deep Learning, Natural Language Processing, Large Language Models, there is so many buzzwords flying around that is easy to get lost in so many terms. Let’s start from the beginning.
Defining the Basics
What is Artificial Intelligence?
Artificial Intelligence is the field of Computer Science that tries to mimic human intelligence to perform different tasks. AI includes Machine Learning and Deep Learning subdomains. It is a very broad field and it includes from simple if-else logics to complex neural networks. Today we have two well-defined subareas: Machine Learning and Deep Learning. Furthermore, there is an overlap with Natural Language Processing.

Machine Learning vs. Deep Learning vs. Natural Language Processing
Machine Learning (ML) is the subarea of Artificial Intelligence in which programs use statistical methods to learn from data without being directly programmed. For example, programs map and predict inputs in regression and classification problems, and output numbers or classes, respectively. On the other hand, Deep Learning (DL) is the subarea in which programs learn on their own to drive decisions from the data. Deep learning can mimic some human capabilities of the brain, for example, Convolution Neural Networks (CNN) can imitate the vision or sight, while Reccurent Neural Networks implements algorithms to copy our memory capability. Natural Language Processing (NLP) is a branch of Artificial Intelligence that focuses on the interaction between computers and humans through natural language. The ultimate objective of NLP is to enable computers to understand, interpret, and generate human language in a way that is both meaningful and useful. This includes tasks such as translation, sentiment analysis, speech recognition, and chatbot development.
While both Machine Learning and Deep Learning techniques are often employed in NLP tasks, the unique challenges of understanding human language – with its nuances, ambiguities, and cultural variations – make NLP a distinct field requiring specialised approaches.
A Closer Look: What are Large Language Models?
Consider the scenario where you have to go through you bank statements to understand where you spend the most for the past six months. Today, the process would consist in accessing to your bank app, downloading the statements and maybe categorize it manually in food, leisure, education, transport, etc. From that, you could then sum all expenses and discover which is your main cost center. With the development of Large Language Models, it is very possible that in the future you will only ask direct to your bank app: “Where does the majority of my money go?”. Large Language Models, often referred to as LLMs, are essentially neural network architectures designed to understand, generate, and interact with human language. They have the ability to understand what a customer is aiming for, retrieve significant information from their requests and provide precise and relevant responses.
For that, LLMs leverage Neural Networks (NN), which are inspired by the human brain and carry this name because of its biological connections and motivations. Just as in the human brain, where the most basic processing unit is the neuron, NNs have an element that processes impulses, or inputs, which is also called a neuron or node. Both structures share the same function for transferring information: they receive an input (impulse) that is carried through the node (cell body) and activate a certain output (axon terminals). Just as in biological neurons, this impulse that fires neurons is reproduced in Neural Networks through activation functions. The way those "brains" work is by saving what they learned in some kind of memory, known as weights or parameters. For a LLM to understand and generate human-like text based on the patterns they've learned, these architectures can have billions, or even trillions, of parameters, which allows them to store and process a vast amount of information. To learn more and have a deep understand how neural networks work, take a look in this article.
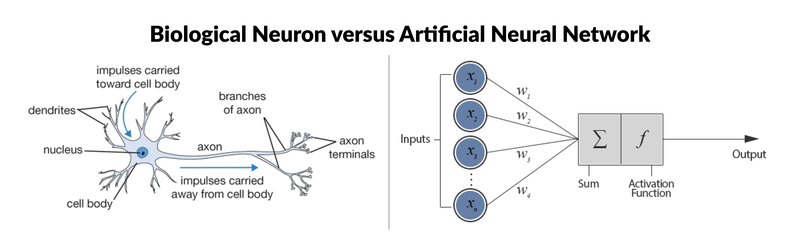
Biological Neuron vs Artificial Neuron. Source: Keras Tutorial: Deep Learning in Python
The evolution of LLMs stems from decades of research in natural language processing and machine learning. Natural language processing (NLP) began with rule-based systems, where linguists manually crafted rules to parse and interpret text. As technology advanced, the field shifted towards statistical models, leveraging probabilities and patterns within vast amounts of data. More recently, the emergence of deep learning has transformed NLP, employing neural networks to capture intricate linguistic nuances. These advancements have propelled NLP from simple text recognition to sophisticated language understanding and generation.
Milestones in NLP: Tracing the Growth of Large Language Models Over the Decades
1960s - Rule-Based Models and Early NLP:
Similar to Artificial Intelligence, NLP is a topic since the 60s. In the earliest days of NLP, systems relied on manually crafted rules to process language.
Late 1980s and 1990s - Statistical Models:
During this period, statistical methods, especially those based on Markov models and Bayesian networks, began to play a significant role in NLP.
Late 1990s and 2000s - Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM):
RNNs and LSTMs emerged as solutions to handle sequences in language processing.
2013 - Word Embeddings:
Word2Vec, introduced by Mikolov et al., was a significant method to represent words in continuous vector spaces.
2017 - Attention Mechanisms and Transformer Architecture:
The Transformer architecture, introduced by Vaswani et al., became a revolutionary method in NLP, largely due to its attention mechanism.
2018 - BERT (Bidirectional Encoder Representations from Transformers):
Google's introduction of BERT set a new standard for context understanding in texts.
2018 - GPT (Generative Pre-trained Transformer):
OpenAI's GPT models, especially the subsequent iterations like GPT-2 and GPT-3, showcased the power of transformer-based models in text generation.
2019 and Beyond - Scaling Up and Specialised LLMs:
The latter part of the decade saw the rise of even larger models with vast numbers of parameters and the emergence of specialised models for distinct tasks.
2020s - Controversies and Ethical Discussions:
As LLMs increased in prominence, the AI community placed a heightened emphasis on discussions regarding their ethical and societal implications.
The real breakthrough happened in 2017 when the Transformers architecture was propose. Together with the Attention Mechanism, they mark the start of the LLMs as we know today. Then the missing gap was closed in the following years: computer power and access to data. As hardware technology progressed, especially with the advent of powerful GPUs and TPUs, researchers gained the capability to process even bigger datasets at unprecedented speeds and efficiencies. This surge in computational power directly facilitated the creation of more complex deep learning architectures, allowing models to handle billions of parameters and achieve finer granularities in language understanding and generation.
One of the remarkable traits of LLMs is their ability to generalize knowledge from one domain to another, showcasing adaptability. The capacity of a model to perform well on unseen data allows us to use them as a base model for several applications. With little to no training a large language model can generate content or answer queries about science, history, marketing and learn information from new documents. Now a days we have examples where the same model serve as basis for assisting in medical research while also crafting creative content in literature or arts.
Difference Between Large Language Models and Traditional Language Models
If NLP is around since the 60s, why just now are we talking a lot about (Large) Language Models? As we saw it before, there was always incremental development in the Natural Language Processing field. These early generation models, or more traditional Language Models, were based in a set of language rules and leverage statistics to predict the probability of the next word in a sentence. Some of these models are still used today for more simple tasks, but they are hindered by some challenges, e.g., contextual words and phrases, because of the absence of additional context outside of a limited window and challenges in capturing distant relationships between words.
Classical NLP involved several algorithms to be able to solve language problems. The traditional approach to NLP tasks involves distinct stages: text preprocessing to simplify vocabulary and remove things like punctuation and stopwords, followed by feature engineering to aid algorithmic learning, often relying on manually designed features aligned with human language understanding. Feature engineering's significance was especially pronounced in classical NLP, with systems showcasing well-crafted features performing best. Learning algorithms then utilize these features, and potentially external resources like WordNet, to excel at tasks, with prediction being the final step.
Some examples of Tradicional Language Models are:
Bag-of-Words (BoW): This approach represents text as a collection of words, ignoring grammar and word order. Each document is represented by a vector indicating the frequency of each word. BoW is simple but lacks contextual understanding.
Term Frequency-Inverse Document Frequency (TF-IDF): TF-IDF considers word frequency within a document balanced against its frequency in the entire corpus. This helps to identify important words specific to a document while downplaying common terms.
N-gram Models: N-grams are sequences of 'n' words. Bigrams (n=2) and trigrams (n=3) capture local word relationships and are used in language modeling, speech recognition, and more.
Hidden Markov Models (HMMs): HMMs are used for tasks involving sequences, like speech recognition and part-of-speech tagging. They model the underlying states that generate sequences of observations.
In contrast, LLMs are based on deep learning architectures like transformers, contain billions or even trillions of parameters, and are trained on vast amounts of diverse data. This scale and complexity allow LLMs not just to predict the next word in a sequence but also to generate coherent, contextually relevant paragraphs, answer complex queries, and even demonstrate rudimentary reasoning, making them far more versatile and powerful than their classical counterparts.
Popular examples of Large Language Models are:
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT is a transformer-based model designed for a wide range of NLP tasks, including text classification, question answering, and more. It's unique because it can pay attention to the words before and after each word, which helps it understand even tricky sentences better.
GPT (Generative Pre-trained Transformer): Created by OpenAI, GPT is a series of generative language models that have been pretrained on large text corpora available in the internet and can generate coherent and contextually relevant text based in statistical properties of language.
T5 (Text-to-Text Transfer Transformer): Also developed by Google, T5 frames most NLP tasks as a text-to-text problem, where both inputs and outputs are treated as text, enabling a unified framework for various tasks. It's trained on big collections of data that include examples of various language tasks like classifying text, making summaries, translating, answering questions, and others. This way, T5 learns how to understand language in a versatile way.
LLAMA (Large Language Model Meta AI): Developed by the FAIR team at Meta AI is an auto-regressive language model based on the transformer architecture. It comes in different sizes, with varying parameters. LLAMA is used for tasks like text generation, document summarization, question answering, and language translation. It's known for coherent text generation and strong language understanding. LLAMA is part of LLaMA (Large Language Model Archive), an open-source initiative that provides access to pre-trained language models for various NLP tasks.
Therefore, the benefits of Large Language Models and the main differences to Tradicional Language Models can be outlined as:
Scale and Size: While Traditional Language Models are typically smaller models, having a limited number of parameters often in the range of thousands to millions, LLMs are built on deep learning architectures and are significantly larger in scale, with hundreds of millions to billions of parameters. This immense scale enables them to capture more complex linguistic patterns and nuances.
Architecture: Pre-deep learning, traditional models heavily relied on rule-based, statistical, or shallow machine learning techniques. Leveraging deep neural network architectures, specifically transformer-based architectures, LLMs can handle long-range dependencies and capture contextual information more effectively.
Performance and Capabilities: Classical models often struggled with capturing complex semantics, context, and understanding nuances in language. They were limited in their ability to perform tasks that require a deep understanding of text. On another hand, Large Language Models have demonstrated remarkable capabilities in understanding context, generating coherent text, answering questions, completing prompts, translating languages, and performing various other language-related tasks with human-like proficiency.
Training Data and Learning: The first generation of NLP models relied on hand-crafted features, rule-based systems, and statistical techniques. They required extensive domain expertise and manual feature engineering. Modern ones, like GPT-4, are trained on massive amounts of text data, allowing them to learn from the data itself rather than relying heavily on predefined features. This data-driven approach, combined with deep learning techniques, results in better adaptability to various domains and tasks.
Generalisation and Transfer Learning: Last but not least, older models often required retraining or significant adaptation when applied to different tasks or domains, while LLMs exhibit strong generalisation and transfer learning capabilities. They can be fine-tuned on specific tasks with relatively smaller amounts of task-specific data, making them versatile and efficient for various applications.
Wrapping Up
In summary, when we navigate the world of AI, it's essential to grasp its fundamentals. We've took a look into the core of AI, explored the difference between Machine Learning and Deep Learning, and explored the impactful role of Natural Language Processing (NLP) in connecting human language with machine comprehension. The rise of Large Language Models (LLMs) emerges as a significant breakthrough and represent a paradigm shift from the limitations of traditional language models due to their sheer size, deep learning architecture, and the ability to learn intricate language patterns. These models, marked by their vastness and importance, are shaping the AI landscape. With LLMs lighting the way ahead, the journey of AI advancement carries on, holding the potential to redefine the realm of human-machine interaction and understanding. By understanding the basics we can appreciate the significance of Large Language Models and their potential to shape the future.